[Up: Distributed Systems]
[Previous: Distributed Systems] [Next: Low-Level Distribution]
The reasons for developing distributed systems
are about as manifold as there are definitions for the term ``distributed system''
in the first place. The most basic one is that of a collaboration of individual
components that communicate to achieve a common goal, which could cover everything
from Unix shell scripts (where various programs communicate using pipes) to
the loose collaborations on the Internet where hundreds or thousands of users
contribute computing power to work on crypto challenges. Both extremes do not
seem so far-fetched when looking at the most popular design strategies used
in distributed systems:
- Parallel processing
- Fault tolerance
- Delegation
- Resource sharing
The first item mentioned here was the historically first, too: when distributing
a single task over a number of processors, parts of the overall task can be
computed in parallel to speed up the total process. Fault tolerance is relevant
in fail-safe systems (e.g. airplanes), and achieved using redundancy: the same
computation is performed multiple times to detect and to safely recover from
the failure of individual nodes. Delegation is the basis of Client/Server systems,
where a server performs a particular service on behalf of the client, like a
database retrieval. Resource sharing is a different kind of delegation, where
systems offer their special information or hardware resources, for example a
graphical X11 display, the operation of a robot or numerical computation capabilities.
Parallel processing, fault tolerance and resource sharing specialize the above
definition of a ``distributed system'' in that they mandate a distribution
over interconnected nodes in a network. This is obvious in the case of parallel
processing, which only makes sense when distributing the job over a number of
distinct processors; and redundancy also can only be achieved with physically
separate systems, because the failure of any part of a node makes any of its
results suspect. However, delegation is just as useful on a single computer,
as in the Unix shell example.
One central keyword in all definitions of distributed systems is communication.
Communication is necessary to distribute information among the components that
make up a distributed system, and to collect the partial results of each component
in order to compute a total answer to the common goal mentioned above.
While the term communication can be stretched to the extreme (global variables
in a program can be said to be a means of communication just as well as common
disk files or shared memory), the usual case of distribution over networked
nodes requires some sort of network-aware transport.
The need of communication, potentially over a shared resource like a network,
introduces a number of potential problems that a distributed system must be
aware of:
- Communication Overhead:
- Transferring data is costly and takes time. Distribution
does not make sense where the time for communication exceeds the amount spent
performing computations. The bandwidth available for communication may be limited
and not constant.
- Points of failure:
- Components can fail individually, or communication links
may fail.
- Security:
- Communication over a public network could be intercepted, manipulated
or interferred with by a third party.
- Synchronization:
- It may be necessary for a distributed system to wait for a
single slow component before computation can continue.
Just as not all of the advantages apply to a given distributed system, the impact
of these potential problems also depends on the particular system which is to
be implemented: while the interception of data by a hostile attacker might be
ignored in a local network, it must be dealt with when private data needs to
be transmitted over the Internet. Depending on the application, the manifold
failure points in communication must be handled specifically. For non-critical
systems, or for small systems in a local network where failure is rare, it may
be acceptable for an application to simply crash in the case of a failure: it
will then be the task of the administrator to discover and correct the cause
of the failure, and to restart the application. In other cases, the software
must be prepared to recover reliably from a partial system failure and perhaps
use redundant components instead.
The term distribution platform shall be used to describe a generic means
of distribution provided by an operating system, library or language. A distribution
platform at least hast to provide primitives for communication and coordination
for use by the programmer to build the distributed system on top of the platform.
It should help a developer to utilize the advantages of a distributed system
as easily as possible while minimizing or at least controlling the potential
problems.
A distribution platform has to provide at least three primitives so that implementing
a distributed system becomes feasible: addressing, synchronization
and encoding.
- Addressing:
- In order for components of a distributed system to find each other,
each must have an address. Servers must be able to publish their address, and
clients must be able to acquire a server's address, either by administrative
intervention, guessing, or looking it up in a naming service.
- Synchronization:
- All participating parties must agree on a certain protocol
when data may be sent or received. Common data transfer protocols are messages,
request-response or data streams.
- Encoding:
- Defines the format used for transferring data. This could be uninterpreted
chunks of octets or structured data.
A distribution platform can be expected to use abstractions of these primitives
to ease development, for example by automated encoding of complex data. In a
synchronized system, the developer is not involved in issues of timing, nor
has to be concerned with the ordering of incoming data. Abstracting all three
issues provides transparency, meaning that the developer does not need to be
aware of how components are located and how data is communicated between them.
Apart from transparency, other key features of distribution platforms are:
- Mobility:
- Components can be fixed to one location, move in an inactive state,
or even move while being active. Mobility can be coarse-grained (servers) or
fine-grained (objects). Location selection could be client-controlled, server-controlled
or automated, with an appropriate location selected by load-balancing, network
usage or hardware requirements.
- Quality of Service:
- Addresses the non-functional aspects of distribution, e.g. a
distributed system's control over different data transports (bandwidth limitations,
encryption), timing (real-time requirements), or protocols to handle redundancy
or error recovery (automated recovery vs. notification vs. abortion).
- Interoperability:
- Closed systems can live without interoperability, but in
a heterogeneous world, it is useful if the distribution platform is not limited
to a particular hardware, operating system or programming language. It is unlikely
that independent clients and servers can agree on identical hardware and software.
A number of distribution platforms have been developed, some with a specific
use like parallel processing in mind, others with the intention of a generic
platform for distributed applications. A couple of examples are explored in
the following sections, grouped by the level of abstraction provided for the
issues above: low, middle or high.
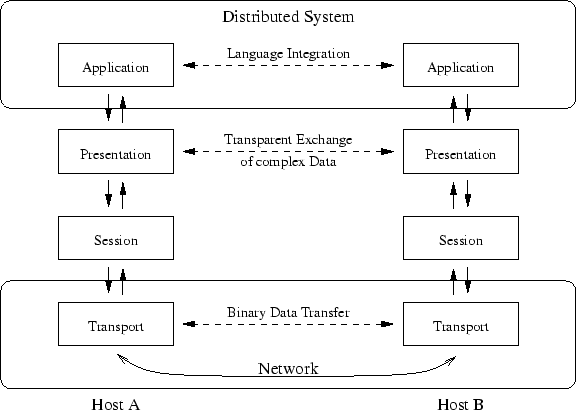
Figure 2.1:
The OSI model applied to Distribution Platforms
|
|
This categorization can be done by applying the popular Open Systems Interconnection
(OSI) Reference Model [70] to distribution platforms.
The OSI model takes a layered approach to networking, each introducing a level
of abstraction. The full model has seven layers, but the lower four, physical,
data link, network and transport, deal with low-level issues such as failure
detection and routing and are of less interest to the application programmer,
who is content with secure communication on top of layer four.
A low-level distribution platform does not abstract any further and allows no
more than data transport. Figure 2.1 shows the upper three
layers of the OSI model on top of the transport layer, with the distributed
system built on the top application layer.
Slightly deviating from OSI terminology, a high-level distribution platform
can be said to provide mechanisms naturally built into the programming language,
so that locality or remoteness is entirely transparent.
The two layers in between, again in line with OSI, provide session control,
the handling of connection between distributed components, and the presentation
layer encodes complex application-dependent data structures like method parameters
into a common format, probably adding data compression or encryption - and
this is just what can be expected from middleware.
[Previous: Distributed Systems] [Next: Low-Level Distribution]
[Up: Distributed Systems]
Frank Pilhofer
1999-06-23